
Maven快速入门
认识Maven没有Maven管理项目会出现的问题
很多模块,模块之间没有关系,手动管理关系,比较繁琐
需要很多第三方功能,需要很多jar文件,需要手动从网络中获取各个jar包
需要管理jar的版本
管理jar文件之间的依赖。项目中a.jar需要用到b.jar里面的类
Maven的用处人工管理项目很麻烦,于是maven就来了,用maven有如下好处:
maven可以管理jar文件
自动下载jar和他的文档,源代码
管理jar直接的依赖,a.jar需要b.jar,maven会自动下载b.jar
管理需要的jar版本
编译、打包、测试、部署程序
Maven的构建构建主要包含项目的编译、测试、运行、打包、部署等,Maven支持的构建包括:
清理(clean),把之前的项目编译的东西删除,为新的编译代码做准备
编译(compile),把程序源代码批量编译为执行代码
测试(test),maven可以执行测试程序代码,验证你的功能是否正确,并生成测试报告
打包(package),把你的项目中所有的class文件,配置文件等所有资源放到一个压缩文件中
这个压缩文件就是项目的结果文件,通常 ...

用户态线程和内核态线程
学习了用户态和内核态,用户态和内核态是内存中完全隔离的两个区域:
内核空间(Kernal Space),这个空间只有内核程序可以访问;
用户空间(User Space),这部分内存专门给应用程序使用。
用户态想要执行系统调用调用时,需要切换到内核态执行
用户态线程用户态线程也称作用户级线程(User Level Thread)。操作系统内核并不知道它的存在,它完全是在用户空间中创建。
用户级线程有很多优势,比如。
管理开销小:创建、销毁不需要系统调用。
切换成本低:用户空间程序可以自己维护,不需要走操作系统调度。
但是这种线程也有很多的缺点。
与内核协作成本高:比如这种线程完全是用户空间程序在管理,当它进行 I/O 的时候,无法利用到内核的优势,需要频繁进行用户态到内核态的切换。
线程间协作成本高:设想两个线程需要通信,通信需要 I/O,I/O 需要系统调用,因此用户态线程需要支付额外的系统调用成本。
无法利用多核优势:比如操作系统调度的仍然是这个线程所属的进程,所以无论每次一个进程有多少用户态的线程,都只能并发执行一个线程,因此一个进程的多个线程无法利用多核的优势。
操作系 ...
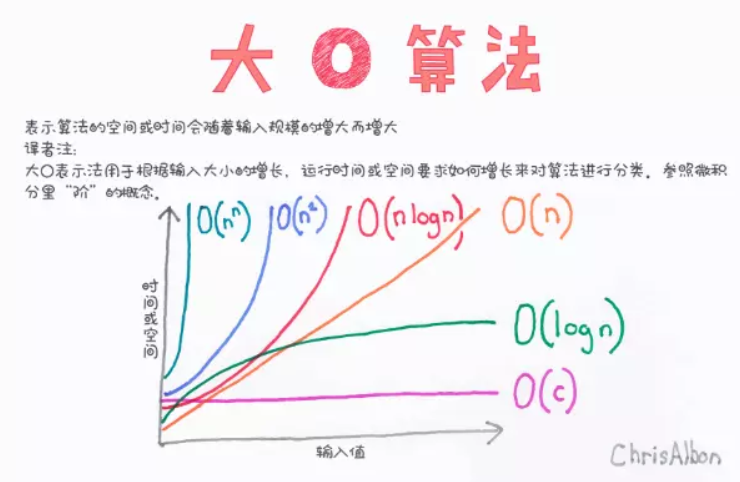
时间复杂度
什么是大O算法导论给出的解释:大O用来表示上界的,当用它作为算法的最坏情况运行时间的上界,就是对任意数据输入的运行时间的上界。
我们看一下快速排序,都知道快速排序是O(nlogn),但是当数据已经有序情况下,快速排序的时间复杂度是O(n^2) 的,**所以严格从大O的定义来讲,快速排序的时间复杂度应该是O(n^2)**。
但是我们依然说快速排序是O(nlogn)的时间复杂度,这个就是业内的一个默认规定,这里说的O代表的就是一般情况,而不是严格的上界。如图所示:
O(logn)中的log是以什么为底?平时说这个算法的时间复杂度是logn的,那么一定是log 以2为底n的对数么?
其实不然,也可以是以10为底n的对数,也可以是以20为底n的对数,但我们统一说 logn,也就是忽略底数的描述。
递归算法的时间复杂度递归算法的时间复杂度本质上是要看: 递归的次数 * 每次递归中的操作次数。
例子:计算x的n次方
最直观的就是用for循环,常规思路:
1234567int function1(int x, int n) { int result = 1; // 注意 任 ...

获取Linux集群免登陆权限
假如有100台服务器,每次都用ssh输入用户名密码的方式登录,这样输入用户名密码就成为一件繁重的工作。
这时候,可以考虑利用主服务器的公钥在各个服务器间登录,避免输入密码。接下来是具体的操作步骤:
生成公私钥对首先,需要在主服务器上用ssh-keygen生成一个公私钥对,然后把公钥写入需要管理的每一台机器的authorized_keys文件中。如下图所示:我们使用ssh-keygen在主服务器中生成公私钥对。
使用mkdir -p创建~/.ssh目录,-p的优势是当目录不存在时,才需要创建,且不会报错。
用cd切换到.ssh目录,然后执行ssh-keygen。这样会在~/.ssh目录中生成两个文件,id_rsa.pub公钥文件和is_rsa私钥文件。
可以看到id_rsa.pub文件中是加密的字符串,我们可以把这些字符串拷贝到其他机器对应用户的~/.ssh/authorized_keys文件中,当ssh登录其他机器的时候,就不用重新输入密码了。
分发公钥我们已经在主服务器生成了公私钥,接下来就需要将公钥分发到其他服务器。这个传播公钥的能力,可以用一个shell脚本执行,这里我用 ...
Linux下修改用户名(同时修改用户组名和家目录)
新装了一个Ubuntu,装好之后给了个默认的用户名,这时候需要重命名用户名,故出此教程。
修改用户名我们使用 usermod 来修改用户名。其语法为:
1$ usermod -l new_username old_username÷
举个例子,假设我们有一个名叫 admin 的用户想要重命名为 jume,并且把家目录也重新命名为jume,那么在终端下执行下面命令:
1$ sudo usermod -l jume -d /home/jume -m admin
这只会更改用户名和家目录,而其他的东西,比如用户组,UID 等都保持不变。
如果当前登录用户是将要修改用户名的用户,系统则会报错
原因是重命名的用户是登录状态,无法进行修改用户名。这时候就需要用另外的用户登录,所以我激活了root用户,切换为root用户之后就可以正常修改用户名。
使用sudo passwd root为root用户设置密码,然后再登录
接下来的操作也需要该用户是未登录状态才可以修改
修改用户 UID执行下面命令修改用户 UID:
1$ sudo usermod -u 2000 jume
这里 2 ...

Reids实现简单分布式锁
什么是分布式锁分布式锁,简单来说就是在分布式环境下(也称为云环境)不同实例之间抢一把锁。
和普通的锁比起来,也就是抢锁的从线程 (协程)变成了实例。
分布式锁之所以难,基本上都和网络有关。
请求可能会超时
怎么设计分布式锁使用redis设计分布式锁可以很容易地想到使用SETNX,设置一个不可更改的键值对。基本过程分为加锁和解锁主要两个操作。在某些需要原子操作的情况下,可以配合lua脚本一起。
加解锁流程
加锁通过SETNX,存入一个key,对应的值是一个随机的uuid,并且需要设置过期时间,最后返回一个Lock结构体。
解锁需要先验证uuid,如果验证成功,则释放锁。
问题
为什么需要设置过期时间?
如果没有过期时间,那么会出现「实例1」抢到锁之后,不小心奔溃了,终止了运行,后续的实例将永远无法获取到锁。
为什么需要设置随机uuid为key的值?
本质上,我们就是需要一个唯一的值,当解锁的时候,需要验证该把锁是不是自己的,防止把其他实例加的锁解锁了。
什么情况下可能会出现错误?
加锁解锁都可能遇到诸如网络错误,redis服务端错误等错误的情况,这种都会将erro返回。
...
Python操作Excel表实例
最近学校整理学籍信息,其中有个需求是将一个总表拆分成若干个表格,首先将总表的每个学生的姓名、学号、联系电话信息提取出来,再根据学生的班级信息进行归类,生成若干个班级表。
总表里有8000多条数据,每条数据有41个信息,分类的班级有接近200个,使用人工一段一段复制肯定是太麻烦的,使用Python操作Excel表可以大大提升我们的工作效率。
Python操作Execl表有许多模块,在多方查资料下,我选择使用Python的openpyxl模块。
这里贴上我学习的网站:https://geek-docs.com/python/python-tutorial/python-openpyxl.html
以及openpyxl的官方Api文档:https://openpyxl.readthedocs.io/en/stable/
基础学习在openpyxl中,主要用到三个概念:Workbooks,Sheets,Cells。
Workbook就是一个excel工作表;
Sheet是工作表中的一张表页;
Cell就是简单的一个格。
openpyxl就是围绕着这三个概念进行的,不管读写都是“三板斧”:打 ...

GoPath 和 GoModule
什么是GoPath?GoPath是Golang的工作空间,所有的Go文件,都需要放在GoPath下的src目录下才能够编译运行,所以我提议不要直接配置全局的GoPath目录,否则会非常难以管理所有的Golang项目。
在项目中使用第三方类库的时候,可以使用go get命令从网下直接拉去第三方类库的包,而拉取下来的包就会直接下载到我们的GoPath目录下的src包下。
但这样就导致了一个问题,我们自己的Golang代码,和第三方的Golang文件混在了一起,这对于我们管理Golang项目的包显然是非常麻烦的,而且每个如果项目都需要「同样的依赖」,那么我们就会在不同的GoPath的src中下载大量重复的第三方依赖包,这同样会占用大量的磁盘空间。
我们给不同的项目设置不同的GoPath,优点非常明显:
便于管理项目,每个项目都是不同的GoPath,这对于我们管理多个Golang项目而言,能够非常清晰的处理项目结构。如果我们把所有项目都放在同一个GoPath的src包下,那么项目的结构就会变得非常混乱,难以管理。
但是当我们需要依赖第三方的包的时候,不同的项目设置不同的GoPath的缺点也非常 ...
Reids快速入门
String是什么?String就是字符串,它是Redis中最基本的数据对象,最大为512MB。
基本操作
写操作SET
语法:SET key value
功能:设置一个key的值为特定的value,成功则返回OK。
String:对象的创建或者更新都是该命令。
12127.0.0.1:6379>SET str catOK
SETNX
语法:SETNX key value
功能:用于在指定的ky不存在时,为key设置指定的值,返回值0表示「key存在」不做操作,1表示设置成功。
如果对存在的Key,调用SETNX:
12127.0.0.1:6379>SETNX str fish (integer)0
对不存在的key,调用SETNX:
12127.0.0.1:6379>SETNX strmart fish(integer)1
DEL
语法:DEL key[key]
功能:删除对象,返回值为删除成功了几行。
12127.0.0.1:6379>DEL str(integer)1
读操作GET
语法:GET key
功能:查询某个key,存在就返回对应的val ...

获取华师砺儒云cookie和sessKey
四史自动刷课脚本说明主要是要获取两个值:cookie和sessKey,下面讲获取方式:
打开砺儒云网页,进入四史,随便选择一个视频页面进入
按F12打开控制台,选择网络(network)栏
点击播放视频,然后再点击暂停视频,这时找到左边请求网址为\service.php的信息
在URL里找到sesskey,下拉在请求标头(request header)里找到cookie,解析出名为MoodleSession的值
将找到的cookie和sessKey填入Python脚本,执行Python脚本,挂后台就可以了


